

Take the power of YOSE to the next level
This is a blog post by Christian Berg, CEO and co-founder of Paliscope. Originally posted on LinkedIn.
One of the most asked questions we receive when presenting YOSE (Your Own Search Engine) has been:
- – “Can we ingest everything we have into YOSE?”
- Our response has always been: “How much data do you have?”
- Often, the response we receive is: “Around 100 million documents…”
We realized that introducing effective search technology for text, images and videos, and integrating it with AI technology would result in YOSE becoming the leading product for intelligence and investigative purposes. This is especially the case given the fact that YOSE uses the latest AI technology to extract intelligence from raw data and information, and make sense of it. YOSE is the most operationally-effective search engine for significantly large volumes of evidence, documents, financial data, research data (to name but a few examples). But….Paliscope has taken YOSE to an even higher level and introduced changes that addresses many of the questions presented to us.
I can now say that our final response would be, “lets have a discussion to see how we can help you.” and for those of you who does not have 100 million files, you are just about to get a YOSE which is a lot faster and smarter.

The three challenges to make YOSE process billions of files
YOSE has a lot of capabilities to extract intelligence from documents, messages, images, and videos… this inevitably presents the user with a significant volume of intelligence. Therefore, we needed to explore ways to effectively store and retrieve data, but to also process it faster. Finally and most importantly, we needed to come up with new ways to interact and analyze all of the data.
This is AI when it is as its best. You stop thinking about AI, it is just there to help you do your job better.
The Challenges we encountered were:
- Interacting with the information. We need to interact with data from the perspective of an intelligence analyst or investigator. But what if you have billions of data points and don’t even know how the needle looks like?
- Storage. How do we store billions of files containing information or data of intelligence / evidence value and retrieve them in the split of a second. Think Google speed.
- Processing. We need to be sure to utilize every piece of the CPU, all the time, when indexing material.

Challenge 1. Interacting with billions of Intelligence Items
We started with the user interface and asked ourselves how does the user wants to interact with the data? That is the most important question.
When you have a lot of data, scrolling or browsing through pages of information to find what you are looking for is not a viable solution anymore (how often do you go to page 2 on Google?) since it is slow, time consuming and you wont see the forest for the trees. Google has the most data and we need to think like Google. First search, then filter the search result. But there is one question that Google does not help you with.
What if you don’t know what to search for? You are looking for a needle in the haystack but you don’t know how the needle looks like.
We needed ways for the analyst or investigator to browse information but without going through thousands and thousands of rows of data…
Natural Language Processing came in to help as it can extract the overall context of the document and information it contains. This means that instead of reading through a significant quantity of documents, the analyst or investigator can browse the extracted intelligence from the documents – saving lots of time and effort which is often crucial during live operations.
It works great! But… What if you have a billion of extracted intelligence, then we have information overload again. The solution was to implement a search engine on top of the extracted intelligence from the Natural Language Processing. The result is magic.

Connecting the Dots with help from Natural Language Processing
Natural Language Processing produces errors; when introducing within the region of a billion files, a link graph could become far too large and unusable. However, our solution to this was to combine new AI technology with the embedded link graph technology from YOSE!
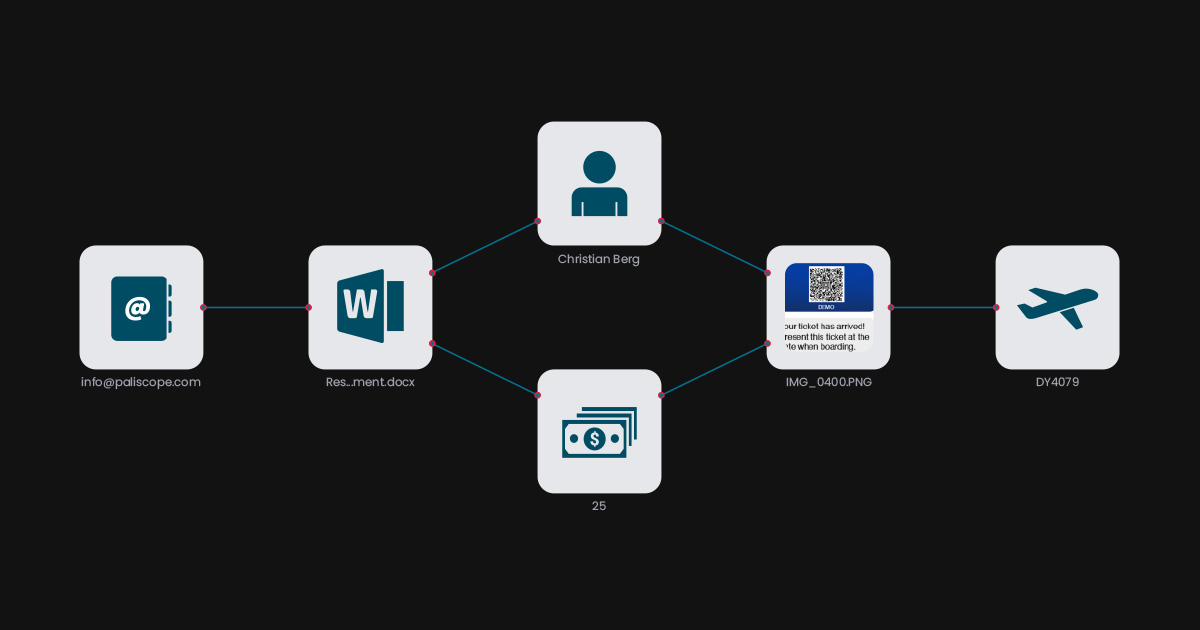
YOSE has a built in visualization feature that enables user to view links between items. Combining NLP with automatic link detection results in the production of link graphs between the extracted intelligence.
This means that a user can choose an account number, bitcoin address, an email… and let YOSE define if there is a relation between them by working its way through all documents, email, chat messages, images, videos…
A positive effect of this is that since we are linking intelligence, the margins of error reduces and the investigator is presented with accurate visual intelligence (this is because YOSE singles out data that has a lower number of links when compared to the real data.)
You may now be thinking that such an intelligence processing and search application would be far too complex to operate – it is not. YOSE is designed with simplicity at the forefront of our minds; at the same time, it is very powerful and lets the intelligence analyst or investigator navigate through billions of files with great ease. You just need to try it out!
The result feels almost magical when you take two pieces of information and let YOSE find the links between them through masses of unstructured information, such as PDF documents, excel spreadsheets, outlook mail boxes, screenshots, images, videos, web crawled data…
Once we cracked the way to interact with a lot of evidence, we continued with the same logic for image search, facial recognition and geo location search.
Guided Search with the help of the context and the extracted intelligence from the AI and the embedded Natural Language Processing engine.
The result is a very fast way to find what you are looking for, supporting very large volumes of data.
How did we solve the storage and processing problem? That is something I save for another article.
Were there any additional challenges you may ask? Of course there were – a lot of them. But we cant give away every little secret we have.
If you have a requirement to search through significant volumes of data and information in rapid speed; apply AI to turn information into actionable intelligence; connect the dots and identify links between documents, chat messages, emails, images and videos, then let us know. Get in touch with the Paliscope team so we can provide you with a live demonstration and provide you with new insight into how you can leverage the super-intelligence processing power of YOSE.





